
A process called retrieval-augmented generation (RAG) is unlocking the kinds of enterprise...

OpenAI made headlines in November 2023 when it announced during their first dev day event that they had adopted retrieval augmented generation (RAG) for ChatGPT. And no, this wasn’t the reason the board fired CEO Sam Altman!
The only ones who seemed to be paying attention to OpenAI’s embrace of RAG were engineers and other artificial intelligence (AI) startups. Considering we’re talking about something called “retrieval augmented generation”, this makes sense. It’s geeky sounding stuff!
But the reality is that RAG is a big deal for the enterprise, and non-technical enterprise leaders also need to understand why.
Here, we explain what RAG is and why it matters — and we’ll try to keep things from getting too technical.
We’ll use simple examples from the financial services industry, which has a very high bar for considering anything to be “enterprise-ready”.
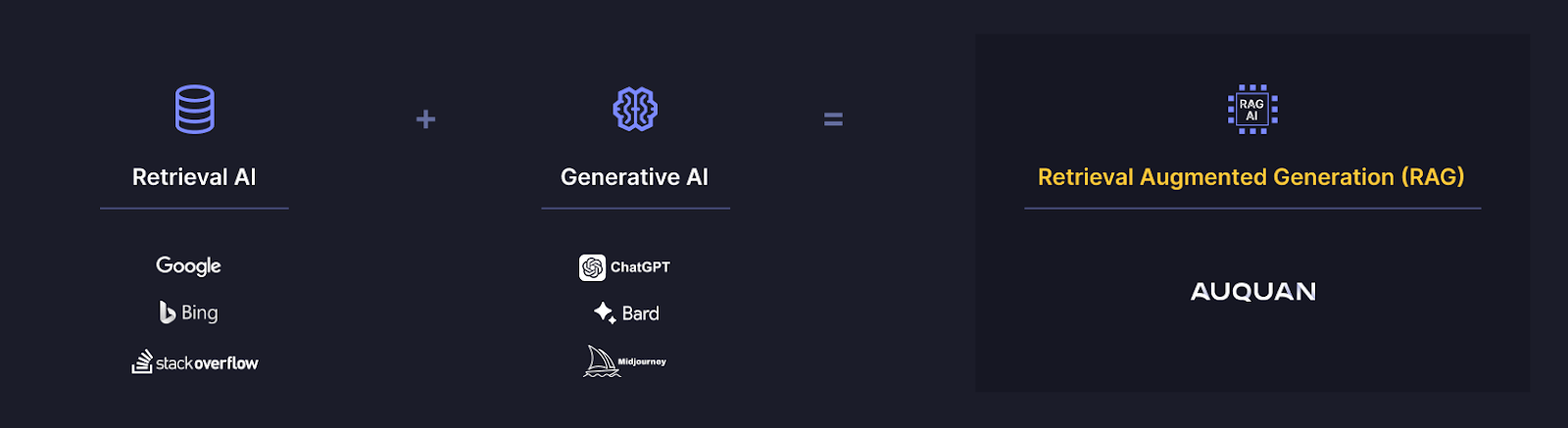
Retrieval augmented generation (RAG) is an AI technique that combines retrieval-based models and their ability to access real-time and external data and find relevant information, with generative models and their ability to create responses in natural language.
There are obvious challenges with using retrieval based search engines like Google. When you ask a question, Google doesn't give you the answer — it gives you the links where the answer might exist. It’s up to you to click through the links Google provides and read them until you find the answer you’re satisfied with.
This process takes time and is inefficient, but you have a high degree of confidence that the answer you have is correct because you have verified the source the information comes from, and you know how recent the information is.
Compare this with a tool like ChatGPT. When you ask it a question, it gives you its answer. At first glance this is great because it's efficient and you've saved time you would’ve spent reading through multiple links. But can you trust the answer? Is it reliable? Does it factor in the latest information? Is it even true?
Now imagine if you could combine these two approaches. When you ask a question, the system first runs a Google search to find the sources that could contain the answer. It then whittles those links down to include only those that are credible, and then passes the text from each of those links to chatGPT, along with the original question. Finally, it asks ChatGPT to produce an answer only based on the text provided to it. If the answer isn’t contained in the text, it won’t provide an answer. And if it does provide an answer, it cites the links it used to generate the answer.
Problem solved! And this is what the beginnings of a RAG system looks like.
To really understand why RAG represents a major breakthrough for the enterprise, the best place to start is by understanding why AI tools like ChatGPT fail in the enterprise when they haven’t integrated RAG.
Think of RAG as an enabling technology — one that can make generative AI tools enterprise-ready.
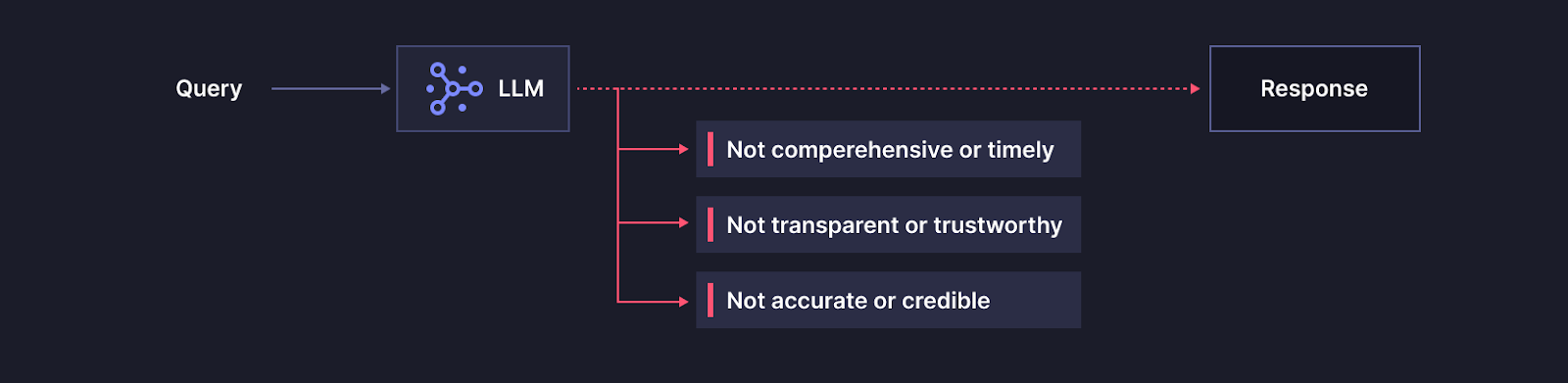
Generative AI tools like ChatGPT use general purpose Large Language Models (LLMs) and are trained on massive amounts of text data to learn the patterns and relationships between words. Training data for general purpose LLMs includes articles, books, and online information.
The training dataset is finite and has a cut-off date, after which no new information is included. This is necessary in order to properly conduct the training process.
When you ask a tool like ChatGPT a question (i.e. “prompt” it), it relies on its training to generate a response for you.
Generative AI based on LLMs — Without RAG
This kind of tool is incredibly useful for helping us to quickly learn about a wide variety of general knowledge topics.
But it has some glaring flaws when it comes to enterprise use cases.
To understand why, let’s first define what we mean by “enterprise-ready” in the context of AI and other information systems.
For any information system to be considered enterprise-ready, it must meet three core criteria:
Generative AI tools like ChatGPT that use general purpose Large Language Models (LLMs) alone fail on all three criteria.
Enterprise AI use cases don’t typically involve generalized tasks or general knowledge, but rather they are knowledge-intensive use cases. That means, in order to be useful, they require the processing of domain-specific and proprietary data in order to produce output that is sufficiently comprehensive for the task at hand.
For example, an analyst may need insights into company-specific risks that require access to niche information such as sanctions lists or shipping data — the kind of information a general purpose LLM isn’t trained on.
Enterprise AI use cases need to factor up-to-date information, but because data used to train LLMs has a cut-off date, the results they produce aren’t timely.
The sanctions lists and shipping data the analyst needs wouldn’t be of much use if they miss recently-applied sanctions or information concerning recent shipments.
LLMs generate new data that's similar to their training data, and therefore they can’t cite sources for the information they produce.
This fundamental lack of transparency creates a trust gap because the information produced is unverified — and difficult or impossible to verify. In the enterprise, you need to back up your analysis with your sources.
For example, a portfolio manager who relies on unverified guidance generated by an LLM brings great risk to investments and reputations — and a loss of trust among clients and regulators. And untraceable data sources could violate industry standards and compliance regulations.
Because LLMs generate net-new information based on the data it was trained on, it has the tendency to produce misleading or outright fabricated responses that appear coherent and credible. This is the infamous “hallucination” problem we’ve all read about and experienced first hand.
While this is a minor nuisance when we’re using LLMs for personal use in order to get a surface-level understanding of a topic, the enterprise has a very different standard for data accuracy. The tendency of LLMs to just make stuff up renders them insufficient for enterprise use cases.
Consider a private credit specialist who uses an LLM to research company risks, and the LLM invents lawsuits against the company out of thin air!
Recall that retrieval-based models can quickly find relevant information from domain-specific or niche datasets, and generative models generate new data based on the massive general purpose dataset they were trained on.
When we combine the two and get retrieval augmented generation (RAG), we can produce a system that is ready to take on knowledge-intensive use cases that require sifting through large volumes of noisy data to generate insights in natural language with a high degree of accuracy and trust.
Here’s how RAG works.
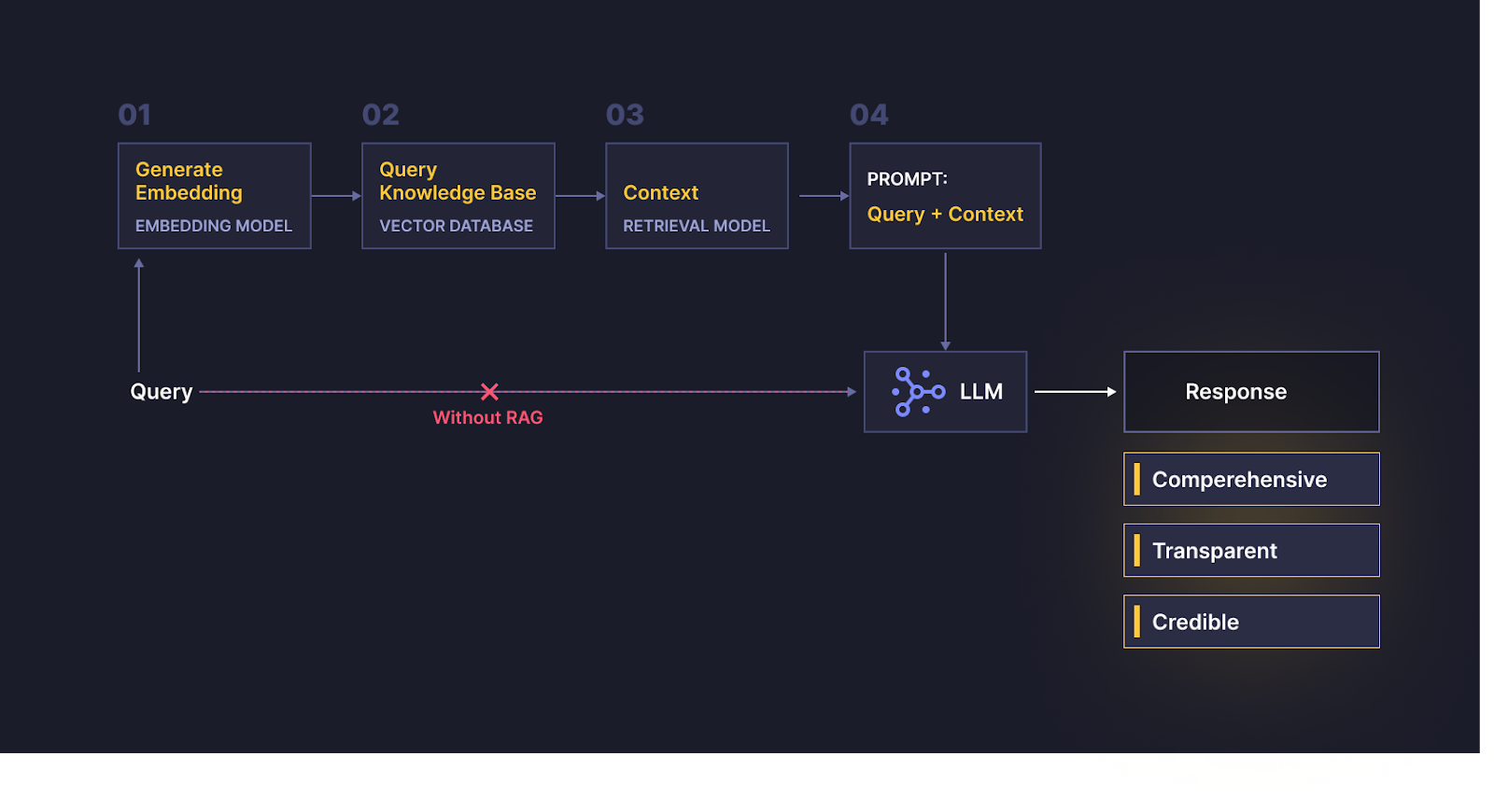
Step 1: Base Prep (vectorisation). When you query or prompt a RAG-based system, it first uses a retrieval engine to find relevant information about your query from pre-selected knowledge sources. In our financial services example, a compliance analyst might query a company name, for example “Tesla”, and the sources might be earnings reports, legal databases, trade journals, broker research and local news stories.
To do this well, the system generates embeddings, which means it converts all text into mathematical vectors in order to understand and match related concepts. In our example, this is how the system is able to know that a document that talks about electric vehicles is relevant to Tesla (the company), while an article about Nikola Tesla isn’t, even though it mentions “Tesla” multiple times.
Step 2: Retrieval. Using a mathematical representation of your query, the system matches it against mathematical representations of all of the sources to find relevant information. In our example, this step may return a large volume of information on Tesla, including its latest earnings call, recent lawsuits, product recalls, customer complaints, expected growth in the EV market, and discounts on Tesla vehicles.
Step 3: Ranking. The system then ranks the relevance of information it retrieves based on a variety of customized criteria, such as your original prompt, your “user persona” or use case, the credibility of the data source, and the information itself. In our example, based on the “compliance analyst” persona, the system will rank information on lawsuits as the most relevant, followed by product recalls, earnings calls, and customer complaints. It might deem EV growth data or vehicle discounts as irrelevant to the user.
Step 4: Generation. The system feeds all information identified as relevant from the selected documents into an LLM, such as GPT4 — along with the original query and appropriate prompt in order to generate the final output for the user. At this stage, the prompt also instructs the LLM to cite the source of any information used in the output. For our example, a response might be:
Tesla, the electric vehicle manufacturer, has faced several legal challenges recently. It was ordered to pay $3.2 million to a former worker who won a lawsuit alleging racial harassment at its Fremont, CA, assembly plant. This case is part of a series of lawsuits involving allegations of discrimination and harassment at Tesla. Additionally, Tesla is involved in lawsuits concerning sexual harassment, wage theft, worker safety violations, and labor law violations related to union activities. Source: Reuters
There has been some scrutiny over Tesla's association with Glencore, a primary supplier of cobalt for Tesla’s electric vehicle batteries, which has been accused of various human rights abuses and corrupt practices in their operations. In their impact reports, Tesla has stated their commitment to responsible mining practices and conducting sustainability audits of their suppliers. Glencore has reportedly completed all required audits and assessments as per Tesla's standards. Source: The Verge
This approach returns far more accurate, comprehensive, and relevant output than a generative AI tool that leverages an LLM alone, which aims only to create fluent output using statistical patterns found in its training data.
Think of RAG as the thing that gives generative AI its enterprise-ready super powers!
Because RAG-based systems can access real-time and domain-specific datasets, their output can be timely and comprehensive.
And RAG-based systems know the specific data sources they use to generate output and can cite them, making them more transparent and trustworthy.
Finally, because RAG-based systems generate output based on the domain-specific datasets they’re provided, the risk of hallucination is significantly reduced, making them far more accurate and credible.
Considering the flaws generative AI tools that use LLMs have, particularly when it comes to the enterprise, OpenAI’s adoption of RAG makes a lot of sense. They’ve closed some big gaps by integrating RAG techniques.
But it doesn’t mean that a tool like ChatGPT is ready to address your enterprise use case right out of the box. But it likely can serve as a platform for you and your team to build a solution that addresses your use case.
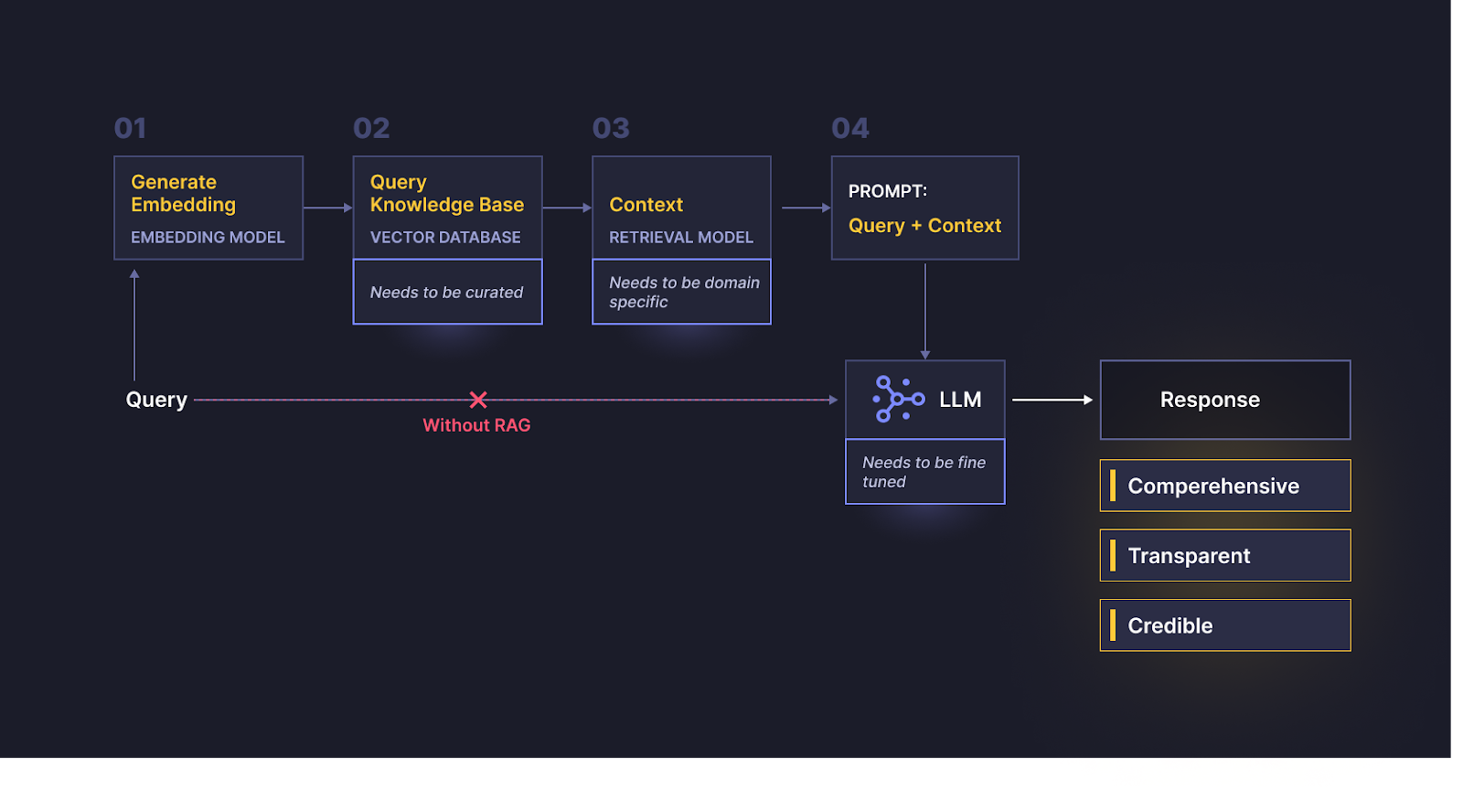
That’s because all enterprise AI use cases are domain-specific ones, not general purpose ones. It takes a really focussed approach to solving a few key workflows with the desired accuracy and performance given the highly verticalized nature of enterprise use cases.
Taking a general purpose RAG-based tool like ChatGPT that uses a general purpose LLM and transforming it into a domain-specific RAG-based solution requires some investment to make it work for your enterprise use case.
An alternative option is domain-specific RAG-based solutions, which are specifically designed to address common enterprise use cases and can typically be easily implemented with little effort or customization required.
For instance, Auquan is an example of a domain-specific RAG-based solution that helps financial services customers uncover actionable intelligence from the world’s unstructured data.
A general rule for enterprise generative AI technology selection:
Read our white paper: The Advantages of RAG AI (Retrieval Augmented Generation) Over Generative AI for Financial Services
A process called retrieval-augmented generation (RAG) is unlocking the kinds of enterprise...

Auquan CEO Chandini Jain spoke with George V. Hulme and Techstrong.ai about enterprise strategies...
.png?height=200&name=Blog%20Post%20Cover%20RAG%20White%20Paper%20(1).png)
Executive Summary In an era where artificial intelligence (AI) influences numerous facets of...
Each day we spotlight under-the-radar investment themes and idiosyncratic risks pulled from our intelligence engine, often involving emerging markets, supply chain issues, ESG risks, and the impact of regulatory changes.

